B-tree
二分木または
B +木
と混同しないでください
でコンピュータサイエンス、B-treeが自己均衡あるツリーデータ構造ソートされたデータを維持し、中に検索し、シーケンシャルアクセス、挿入、および削除を可能に対数時間。Bツリーは二分探索木を一般化し、3つ以上の子を持つノードを可能にします。他の自己平衡二分探索木とは異なり、Bツリーはディスクなどの比較的大きなデータブロックを読み書きするストレージシステムに最適です。これは、データベースやファイルシステムで一般的に使用されています。Bツリー タイプ
ツリー(データ構造)
発明された 1970 によって発明された
ルドルフ・バイヤー、エドワード・M・マクレイト
時間複雑で大きなO記法
アルゴリズム
平均
最悪の場合
スペース
O(n)
O(n)
検索
O(log n)
O(log n)
入れる
O(log n)
O(log n)
消去
O(log n)
O(log n)
コンテンツ 1 元 2 意味
2.1 用語の違い
3 非公式の説明
3.1 バリアント
4 データベースでのBツリーの使用
4.1 ソートされたファイルを検索する時間 4.2 インデックスは検索を高速化します 4.3 挿入と削除 4.4 データベースでのBツリー使用の利点
5 最良の場合と最悪の場合の高さ
6 アルゴリズム
6.1 検索 6.2 挿入 6.3 消す
6.3.1 リーフノードからの削除
6.3.2 内部ノードからの削除
6.3.3 削除後のリバランス
6.4 シーケンシャルアクセス 6.5 初期工事
7 ファイルシステム内
8 パフォーマンス
9 バリエーション
9.1 並行性へのアクセス 9.2 並列アルゴリズム
10 も参照してください
11 ノート
12 参考文献
12.1 オリジナルペーパー
13 外部リンク
元
Bツリーは、大きなランダムアクセスファイルのインデックスページを効率的に管理する目的で、ボーイング研究所で働いていたときにルドルフバイヤーとエドワードM.マクレイトによって発明されました。基本的な仮定は、インデックスが非常に大量であるため、ツリーの小さなチャンクのみがメインメモリに収まるというものでした。バイエルとマクレイトの論文「大規模な順序付けされたインデックスの編成と保守」は、1970年7月に最初に配布され、後にActaInformaticaで公開されました。
バイエルとマクレイトは、Bが何を表すのかを説明したことはありません。ボーイング、バランスの取れた、広い、ふさふさした、バイエルが提案されています。 McCreightは、「BツリーのBが何を意味するのかを考えれば考えるほど、Bツリーをよりよく理解できる」と述べています。
意味
Knuthの定義によれば、次数mのBツリーは、次の特性を満たすツリーです。
すべてのノードには最大でm個の子が(ルートを除く)すべての非リーフノードは、少なくとも⌈有するM /2⌉子ノード。
ルートがリーフノードでない場合、ルートには少なくとも2つの子が
非リーフノードk個の子どもたちが含まれているK 1つのキーを- 。
すべての葉は同じレベルに表示され、情報はありません。
各内部ノードのキーは、そのサブツリーを分割する分離値として機能します。内部ノード3つの子ノード(またはサブツリー)を有する場合、例えば、それは2つのキー有していなければならない1及び2。左端のサブツリーのすべての値未満であろう1、中間サブツリー内のすべての値は、の間であろう1及び2、及び右端のサブツリー内のすべての値がより大きくなる2。
内部ノード
内部ノードは、リーフノードとルートノードを除くすべてのノードです。それらは通常、要素と子ポインタの順序付けられたセットとして表されます。すべての内部ノードが含まれている
最大の
Uの子供と
最小の
Lの子供たちを。したがって、要素の数は常に子ポインタの数より1少なくなります(要素の数はL -1と
U -1の間にあります)。
Uは2Lまたは
2L -1のいずれかでなければなりません
。したがって、各内部ノードは少なくとも半分がいっぱいです。Uと
Lの関係は
、2つのハーフフルノードを結合してリーガルノードを作成し、1つのフルノードを2つのリーガルノードに分割できることを意味します(1つの要素を親にプッシュする余地がある場合)。これらのプロパティを使用すると、新しい値を削除してBツリーに挿入し、ツリーを調整してBツリーのプロパティを保持できます。
ルートノード
ルートノードの子の数には、内部ノードと同じ上限がありますが、下限はありません。たとえば、ツリー全体にL -1未満の
要素がある場合、ルートはツリー内で子がまったくない唯一のノードになります。
リーフノード
Knuthの用語では、リーフノードは情報を伝達しません。リーフの1レベル上の内部ノードは、他の作成者によって「リーフ」と呼ばれるものです。これらのノードは、キー(最大でm -1、ルートでない場合は少なくとも
m / 2-1 )のみを格納します。
情報を持たないノードへのポインタ。
深さのBツリーのn +1は約保持することができますUの深さのBツリーなど、多くの項目として倍のnが、検索、挿入、および削除操作のコストは、ツリーの深さに成長します。他のバランスの取れたツリーと同様に、コストは要素の数よりもはるかにゆっくりと増加します。
一部のバランスの取れたツリーは、リーフノードにのみ値を格納し、リーフノードと内部ノードに異なる種類のノードを使用します。Bツリーは、リーフノードを除くツリー内のすべてのノードの値を保持します。
用語の違い
Bツリーに関する文献は、その用語が統一され
Bayer and McCreight(1972)、 Comer(1979)、などは、Bツリーの順序を非ルートノードのキーの最小数として定義しています。は、キーの最大数が明確でないため、用語があいまいであると指摘しています。オーダー3のBツリーは、最大6つのキーまたは最大7つのキーを保持できます。Knuth(1998)は、順序を子の最大数(キーの最大数より1つ多い)に定義することで問題を回避しています。
葉という用語も一貫性がありません。Bayer and McCreight(1972)は、リーフレベルをキーの最低レベルと見なしましたが、クヌースはリーフレベルを最低キーの1レベル下と見なしました。多くの可能な実装の選択肢が一部の設計では、リーフがデータレコード全体を保持する場合が他の設計では、リーフはデータレコードへのポインタのみを保持する場合がこれらの選択は、Bツリーの概念の基本ではありません。
簡単にするために、ほとんどの作成者は、ノードに収まるキーの数が固定されていると想定しています。基本的な前提は、キーサイズが固定され、ノードサイズが固定されていることです。実際には、可変長キーを使用することができます。
非公式の説明

5次( Knuth 1998)のBツリー( Bayer&McCreight 1972)。
Bツリーでは、内部(非リーフ)ノードは、事前定義された範囲内で可変数の子ノードを持つことができます。データがノードに挿入またはノードから削除されると、その子ノードの数が変化します。事前定義された範囲を維持するために、内部ノードを結合または分割することができます。子ノードの範囲が許可されているため、Bツリーは他の自己平衡探索木ほど頻繁に再平衡化する必要はありませんが、ノードが完全にいっぱいではないため、スペースを浪費する可能性が子ノードの数の下限と上限は、通常、特定の実装に対して固定されています。たとえば、2–3ツリー(2–3 Bツリーと呼ばれることもあります)では、各内部ノードに2つまたは3つの子ノードしかない場合が
Bツリーの各内部ノードには、いくつかのキーが含まれています。キーは、サブツリーを分割する分離値として機能します。たとえば、内部ノードに3つの子ノード(またはサブツリー)がある場合、2つのキーが必要です。 1
{a_ {1}}
と 2
{a_ {2}}
。左端のサブツリーのすべての値は、より小さくなります 1
{a_ {1}}
、中央のサブツリーのすべての値は 1
{a_ {1}}
と 2
{a_ {2}}
、および右端のサブツリーのすべての値は 2
{a_ {2}}
。
通常、キーの数は間で変化するように選択されます {d}
と
2 {2d}
、 どこ {d}
キーの最小数であり、 + 1 {d + 1}
ツリーの最小次数または分岐係数です。実際には、キーはノード内で最も多くのスペースを占有します。係数2は、ノードを分割または結合できることを保証します。内部ノードに
2 {2d}
キーを作成し、そのノードにキーを追加するには、仮想を分割します。
2 + 1 {2d + 1}
キーノードを2つに {d}
キーノードと、中央にあったはずのキーを親ノードに移動します。各分割ノードには、必要な最小数のキーが同様に、内部ノードとその隣接ノードがそれぞれ {d}
キーの場合、キーを隣接ノードと組み合わせることにより、キーを内部ノードから削除できます。キーを削除すると、内部ノードに − 1 {d-1}
キー; 隣人に参加すると追加されます {d}
キーに加えて、隣人の親から持ち込まれたもう1つのキー。結果は完全に完全なノードです
2 {2d}
キー。
ノードからのブランチ(または子ノード)の数は、ノードに格納されているキーの数より1つ多くなります。2–3 Bツリーでは、内部ノードは1つのキー(2つの子ノードを持つ)または2つのキー(3つの子ノードを持つ)のいずれかを格納します。Bツリーはパラメータで記述されることがあります(( + 1 )。
{ displaystyle(d + 1)}
—(( 2 + 1 )。
{ displaystyle(2d + 1)}
または単に最高の分岐順序で、(( 2 + 1 )。
{ displaystyle(2d + 1)}
。
Bツリーは、挿入後、いっぱいになる可能性のあるノードを分割することにより、バランスが保たれます。
2 + 1 {2d + 1}
キー、2つに {d}
-キーの兄弟と中間値キーを親に挿入します。深さは、ルートが分割されたときにのみ増加し、バランスを維持します。同様に、Bツリーは、削除後、兄弟間でキーをマージまたは再配布して、 {d}
-非ルートノードのキーの最小値。マージにより、親内のキーの数が減り、兄弟とのキーのマージまたは再配布などが強制される可能性が深さの唯一の変化は、ルートに2つの子がある場合に発生します。 {d}
および(一時的に) − 1 {d-1}
キー。この場合、2つの兄弟と親がマージされ、深さが1つ減ります。
この深さは、要素がツリーに追加されるにつれてゆっくりと増加しますが、全体的な深さの増加はまれであり、すべてのリーフノードがルートからもう1つのノードになります。
ノードのデータにアクセスする時間がそのデータの処理に費やされる時間を大幅に超える場合、Bツリーには代替実装に比べて大きな利点がこれは、ノードへのアクセスのコストがノード内の複数の操作で償却される可能性があるためです。これは通常、ノードデータがディスクドライブなどのセカンダリストレージにある場合に発生します。各内部ノード内のキーの数を最大化することにより、ツリーの高さが減少し、コストのかかるノードアクセスの数が減少します。さらに、ツリーのリバランスが発生する頻度は低くなります。子ノードの最大数は、子ノードごとに格納する必要のある情報と、フルディスクブロックのサイズまたはセカンダリストレージの類似のサイズによって異なります。2〜3個のBツリーは説明が簡単ですが、セカンダリストレージを使用する実際のBツリーでは、パフォーマンスを向上させるために多数の子ノードが必要です。
バリアント
Bツリーという用語は、特定のデザインを指す場合もあれば、一般的なクラスのデザインを指す場合も狭義には、Bツリーはその内部ノードにキーを格納しますが、リーフのレコードにそれらのキーを格納する必要はありません。一般的なクラスには、B +ツリー、B *ツリー、B * +ツリーなどのバリエーションが含まれます。
でB +木、キーのコピーは内部ノードに格納されています。キーとレコードはリーフに保存されます。さらに、リーフノードには、シーケンシャルアクセスを高速化するために次のリーフノードへのポインタが含まれる場合が
B *ツリーは、より多くの隣接する内部ノードのバランスを取り、内部ノードをより密にパックします。このバリアントは、非ルートノードが1/2ではなく少なくとも2/3いっぱいになることを保証します。ノードをBツリーに挿入する操作の最もコストのかかる部分はノードの分割であるため、分割操作を可能な限り延期するためにB *ツリーが作成されます。これを維持するために、ノードがいっぱいになったときにすぐに分割するのではなく、そのキーはその隣のノードと共有されます。このスピル操作は、既存のノード間でキーをシフトするだけで、新しいノードにメモリを割り当てる必要がないため、分割よりもコストがかかりません。挿入の場合、最初にノードに空き領域があるかどうかがチェックされ、ある場合は、新しいキーがノードに挿入されます。ただし、ノードがいっぱいの場合(m − 1キーがあり、mは1つのノードからのサブツリーへのポインターの最大数としてのツリーの順序です)、正しい兄弟が存在し、空き領域があるかどうかを確認する必要が 。右の兄弟がj < m − 1のキーを持っている場合、キーは2つの兄弟ノード間で可能な限り均等に再配布されます。この目的のために、現在のノードからのm -1キー、挿入された新しいキー、親ノードからの1つのキー、および兄弟ノードからのjキーは、m + j +1キーの順序付けられた配列と見なされます。配列は半分に分割されるため、⌊(m + j + 1)/ 2⌋の最下位のキーは現在のノードに残り、次の(中央の)キーは親に挿入され、残りは右の兄弟に移動します。(新しく挿入されたキーは3つの場所のいずれかに終わる可能性が)右の兄弟がいっぱいで、左がいっぱいでない場合の状況は類似しています。両方の兄弟ノードがいっぱいになると、2つのノード(現在のノードと兄弟)が3つに分割され、もう1つのキーがツリーの上位の親ノードにシフトされます。親がいっぱいの場合、スピル/スプリット操作はルートノードに向かって伝播します。ただし、ノードの削除は挿入よりもいくらか複雑です。
B * +ツリーは、メインのB +ツリーとB *ツリーの機能を組み合わせたものです。
Bツリーを順序統計ツリーに変換して、キー順でN番目のレコードをすばやく検索したり、任意の2つのレコード間のレコード数をカウントしたり、その他のさまざまな関連操作を実行したりできます。
データベースでのBツリーの使用
ソートされたファイルを検索する時間
通常、ソートおよび検索アルゴリズムは、順序表記を使用して実行する必要のある比較操作の数によって特徴付けられています。バイナリサーチとソートテーブルのN個のレコードは、例えば、大まかに行うことができるログ⌈ 2 N ⌉比較します。テーブルには1,000,000レコードを持っていた場合には、特定のレコードは、ほとんどの20個の比較にして配置することができる:⌈ログイン2(1,000,000)⌉= 20。
大規模なデータベースは、これまでディスクドライブに保存されてきました。ディスクドライブ上のレコードを読み取る時間は、レコードが使用可能になったらキーを比較するために必要な時間をはるかに超えています。ディスクドライブからレコードを読み取る時間には、シーク時間と回転遅延が含まれます。シーク時間は0〜20ミリ秒以上で、回転遅延は平均して回転周期の約半分です。7200 RPMドライブの場合、ローテーション期間は8.33ミリ秒です。Seagate ST3500320NSなどのドライブの場合、トラック間のシーク時間は0.8ミリ秒で、平均読み取りシーク時間は8.5ミリ秒です。簡単にするために、ディスクからの読み取りに約10ミリ秒かかると仮定します。
したがって、単純に、100万から1つのレコードを見つけるのにかかる時間は、20回のディスク読み取りに10ミリ秒を掛けたものになります。これは0.2秒です。
個々のレコードがディスクブロックにグループ化されているため、時間はそれほど悪くはありません。ディスクブロックは16キロバイトである可能性が各レコードが160バイトの場合、100レコードを各ブロックに格納できます。上記のディスク読み取り時間は、実際にはブロック全体でした。ディスクヘッドが所定の位置に配置されると、1つまたは複数のディスクブロックをほとんど遅延なく読み取ることができます。ブロックあたり100レコードの場合、最後の6程度の比較では、ディスク読み取りを行う必要はありません。比較はすべて、最後に読み取られたディスクブロック内で行われます。
検索をさらに高速化するには、最初の13から14の比較(それぞれディスクアクセスが必要)を高速化する必要が
インデックスは検索を高速化します
Bツリーインデックスは、データベースを固定サイズのブロックまたはページに分割するマルチレベルのツリー構造を作成します。このツリーの各レベルを使用して、アドレスの場所を介してこれらのページをリンクし、1つのページ(ノードまたは内部ページと呼ばれる)が最下位レベルのリーフページを持つ別のページを参照できるようにします。通常、1ページがツリーの開始点、つまり「ルート」です。これは、特定のキーの検索が開始され、リーフで終了するパスをトラバースする場所です。この構造のほとんどのページは、最終的に特定のテーブル行を参照するリーフページになります。
Bツリーインデックスを使用すると、パフォーマンスを大幅に向上させることができます。各ノード(または内部ページ)には3つ以上の子を含めることができるため、Bツリーインデックスは通常、バイナリ検索ツリーよりも高さ(ルートから最も遠いリーフまでの距離)が短くなります。上記の例では、最初のディスク読み取りにより、検索範囲が2分の1に狭まりました。これは、各ディスクブロックの最初のレコードを含む補助インデックス(スパースインデックスと呼ばれることもあります)を作成することで大幅に改善できます。この補助インデックスは、元のデータベースのサイズの1%になりますが、より迅速に検索できます。補助インデックスでエントリを見つけると、メインデータベースで検索するブロックがわかります。補助インデックスを検索した後、メインデータベースのその1つのブロックのみを検索する必要がありますが、ディスクの読み取りが1つ増える必要がインデックスは10,000エントリを保持するため、最大14回の比較が必要になります。メインデータベースと同様に、補助インデックスの最後の6つほどの比較は、同じディスクブロック上で行われます。インデックスは約8回のディスク読み取りで検索でき、目的のレコードには9回のディスク読み取りでアクセスできます。
補助インデックスを作成するトリックを繰り返して、補助インデックスの補助インデックスを作成できます。これにより、100エントリのみを必要とし、1つのディスクブロックに収まるaux-auxインデックスが作成されます。
14個のディスクブロックを読み取って目的のレコードを見つける代わりに、3個のブロックを読み取るだけで済みます。このブロッキングは、ディスクブロックがインデックスを構成するレベルの階層を埋めるBツリーの作成の背後にある中心的なアイデアです。ツリーのルートであるaux-auxインデックスの最初の(そして唯一の)ブロックを読み取って検索すると、下のレベルのaux-index内の関連するブロックが識別されます。そのaux-indexブロックを読み取って検索すると、リーフレベルと呼ばれる最終レベルがメインデータベース内のレコードを識別するまで、読み取る関連ブロックが識別されます。150ミリ秒ではなく、30ミリ秒でレコードを取得できます。
補助インデックスは大体必要とバイナリ検索から探索問題になっているログ2 Nディスクのみ必要一つに読み出すログbが Nの場合、ディスクの読み取りbはブロッキング因子(ブロック当たりのエントリの数である:B = 100のにおけるブロック毎のエントリ私たち例; log 100 1,000,000 = 3回の読み取り)。
実際には、メインデータベースが頻繁に検索される場合、aux-auxインデックスとauxインデックスの多くがディスクキャッシュに存在する可能性があるため、ディスクの読み取りは発生しません。Bツリーは、ほとんどすべてのリレーショナルデータベースで標準のインデックス実装のままであり、多くの非リレーショナルデータベースでもBツリーが使用されています。
挿入と削除
データベースが変更されない場合、インデックスのコンパイルは簡単であり、インデックスを変更する必要はありません。変更がある場合、データベースとそのインデックスの管理はより複雑になります。
データベースからレコードを削除するのは比較的簡単です。インデックスは同じままで、レコードに削除済みのマークを付けることができます。データベースはソートされた順序のままです。削除が多数あると、検索と保存の効率が低下します。
挿入されたレコード用のスペースを確保する必要があるため、ソートされたシーケンシャルファイルでは挿入が非常に遅くなる可能性が最初のレコードの前にレコードを挿入するには、すべてのレコードを1つ下にシフトする必要がこのような操作は、費用がかかりすぎて実用的ではありません。1つの解決策は、いくつかのスペースを残すことです。ブロック内のすべてのレコードを密にパックする代わりに、ブロックには、後続の挿入を可能にするための空きスペースを含めることができます。これらのスペースは、「削除された」レコードであるかのようにマークされます。
ブロックにスペースがあれば、挿入と削除の両方が高速です。挿入がブロックに収まらない場合は、近くのブロックに空きスペースを見つけて、補助インデックスを調整する必要が多くのブロックを再編成する必要がないように、近くに十分なスペースが利用できることが望まれます。あるいは、いくつかの順不同のディスクブロックが使用される場合が
データベースでのBツリー使用の利点
Bツリーは、上記のすべてのアイデアを使用します。特に、Bツリー:
シーケンシャルトラバースのためにキーをソートされた順序で保持します
階層インデックスを使用して、ディスク読み取りの数を最小限に抑えます
部分的に完全なブロックを使用して、挿入と削除を高速化します
再帰的アルゴリズムでインデックスのバランスを保ちます
さらに、Bツリーは、内部ノードが少なくとも半分満たされていることを確認することにより、無駄を最小限に抑えます。Bツリーは、任意の数の挿入と削除を処理できます。
最良の場合と最悪の場合の高さ
ましょH ≥-1(参照古典的なBツリーの高さツリー(データ構造)§用語樹高定義用)。してみましょうnは0≥ツリー内のエントリの数とします。ましょう、mはノードが持つことのできる子の最大数とします。各ノードは最大m -1個のキーを持つことができます。
すべてのノードが完全に満たされた高さhのBツリーにはn = m h +1 –1エントリがあることを(たとえば誘導によって)示すことができます。したがって、Bツリーの最良の高さ(つまり最小の高さ)は次のとおりです。 I = ⌈ ログ (( + 1 )。⌉ − 1
{h _ { mathrm {min}} = lceil log _ {m}(n + 1) rceil -1}
させて {d}
内部(非ルート)ノードが持つことができる子の最小数である。通常のBツリーの場合、 =
⌈ / 2 ⌉ {d = left lceil m / 2 right rceil。}
Comer(1979)およびCormen etal。(2001)Bツリーの最悪の場合の高さ(最大の高さ)をとして与えます。= ⌊ ログ +1 2
⌋ {h _ { mathrm {max}} = left lfloor log _ {d} { frac {n + 1} {2}} right rfloor。}
アルゴリズム
特に、以下の説明では、「要素」、「値」、「キー」、「セパレーター」、および「分離値」を使用して、本質的に同じことを意味します。用語は明確に定義され根と葉にはいくつかの微妙な問題が
検索
検索は、二分探索木の検索に似ています。ルートから開始して、ツリーは再帰的に上から下にトラバースされます。各レベルで、検索は視野を子ポインター(サブツリー)に縮小します。その範囲には検索値が含まれます。サブツリーの範囲は、その親ノードに含まれる値またはキーによって定義されます。これらの制限値は、分離値とも呼ばれます。
バイナリ検索は通常(必ずしもそうとは限りませんが)ノード内で使用され、対象の分離値と子ツリーを見つけます。
挿入
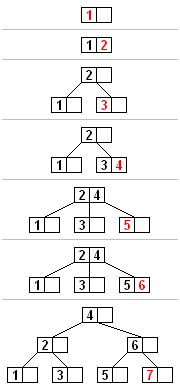
反復ごとのABツリー挿入の例。このBツリーのノードには、最大3つの子があります(クヌース次数3)。
すべての挿入はリーフノードから始まります。新しい要素を挿入するには、ツリーを検索して、新しい要素を追加する必要があるリーフノードを見つけます。次の手順で、新しい要素をそのノードに挿入します。
ノードに含まれる要素の最大数より少ない場合は、新しい要素のための余地がノードの要素を順序付けたまま、新しい要素をノードに挿入します。
それ以外の場合、ノードはいっぱいになり、2つのノードに均等に分割します。
葉の要素と新しい要素の中から単一の中央値が選択されます。
中央値よりも小さい値は新しい左ノードに配置され、中央値よりも大きい値は新しい右ノードに配置され、中央値は分離値として機能します。
分離値はノードの親に挿入されるため、分割される可能性がノードに親がない場合(つまり、ノードがルートであった場合)、このノードの上に新しいルートを作成します(ツリーの高さを増やします)。
分割がルートまで続く場合、単一のセパレータ値と2つの子を持つ新しいルートが作成されます。そのため、内部ノードのサイズの下限はルートに適用されません。ノードあたりの要素の最大数はU -1です。ノードが分割されると、1つの要素が親に移動しますが、1つの要素が追加されます。したがって、要素の最大数U -1を2つの有効なノードに分割できる必要がこの数が奇数の場合、U = 2 Lであり、新しいノードの1つには(U -2)/ 2 = L -1要素が含まれているため、正当なノードであり、もう1つにはもう1つの要素が含まれているため、合法でも場合Uは-1さえ、次いでUは2 = Lを-1、SO 2が存在するL -2ノード内の要素は。この数の半分はL -1であり、これはノードごとに許可される要素の最小数です。
別のアルゴリズムは、ルートから挿入が行われるノードへのツリーのシングルパスをサポートし、途中で検出されたノード全体をプリエンプティブに分割します。これにより、親ノードをメモリに呼び戻す必要がなくなります。これは、ノードがセカンダリストレージにある場合にコストがかかる可能性がただし、このアルゴリズムを使用するには、新しい要素を追加せずに、1つの要素を親に送信し、残りのU -2要素を2つの有効なノードに分割できる必要がこれには、U = 2 L -1ではなくU = 2 Lが必要です。これは、なぜいくつかの教科書は、Bツリーを定義する際にこの要件を課しています。
消す
Bツリーから削除するための2つの一般的な戦略が
アイテムを見つけて削除し、ツリーを再構築してその不変条件を保持する、または
ツリーを1回パスしますが、ノードに入る(アクセスする)前に、ツリーを再構築して、削除するキーが見つかったら、それ以上再構築する必要なしに削除できるようにします。
以下のアルゴリズムは前者の戦略を使用しています。
要素を削除する際に考慮すべき2つの特別なケースが
内部ノードの要素は、その子ノードの区切り文字です
要素を削除すると、そのノードが最小数の要素と子の下に配置される場合があります
これらの場合の手順は以下のとおりです。
リーフノードからの削除
削除する値を検索します。
値がリーフノードにある場合は、ノードから削除するだけです。
アンダーフローが発生した場合は、以下の「削除後のリバランス」の説明に従ってツリーのバランスを取り直して
内部ノードからの削除
内部ノードの各要素は、2つのサブツリーの分離値として機能するため、分離の代わりを見つける必要が左側のサブツリーの最大要素はまだセパレータよりも小さいことに注意して同様に、右側のサブツリーの最小要素は、区切り文字よりも大きくなります。これらの要素は両方ともリーフノードにあり、どちらか一方を2つのサブツリーの新しい区切り文字にすることができます。以下にアルゴリズムで説明します。
新しいセパレーター(左側のサブツリーで最大の要素または右側のサブツリーで最小の要素)を選択し、それが含まれているリーフノードから削除して、削除する要素を新しいセパレーターに置き換えます。
前の手順で、リーフノードから要素(新しいセパレータ)を削除しました。そのリーフノードが不足している(必要なノード数より少ない)場合は、リーフノードから開始してツリーのバランスを取り直します。
削除後のリバランス
リバランスは葉から始まり、ツリーのバランスがとれるまでルートに向かって進みます。ノードから要素を削除すると、その要素が最小サイズを下回った場合、すべてのノードを最小にするために、一部の要素を再配布する必要が通常、再配布には、ノードの最小数を超える兄弟ノードから要素を移動することが含まれます。この再配布操作はローテーションと呼ばれます。兄弟が要素をスペアできない場合は、不足しているノードを兄弟とマージする必要がマージにより、親はセパレータ要素を失うため、親が不足し、リバランスが必要になる場合がマージとリバランスは、ルートまで続く場合が最小要素数はルートには適用されないため、ルートを唯一の欠陥ノードにすることは問題ではありません。ツリーのバランスを取り直すアルゴリズムは次のとおりです。
不足しているノードの右の兄弟が存在し、最小数を超える要素がある場合は、左に回転します
親から不足しているノードの最後にセパレーターをコピーします(セパレーターは下に移動します。不足しているノードの要素数は最小になります)
親のセパレータを右の兄弟の最初の要素に置き換えます(右の兄弟は1つのノードを失いますが、少なくとも最小数の要素があります)
木はバランスが取れています
それ以外の場合、不足しているノードの左側の兄弟が存在し、最小数を超える要素がある場合は、右に回転します
親から不足しているノードの先頭にセパレーターをコピーします(セパレーターは下に移動します。不足しているノードの要素数は最小になります)
親のセパレータを左の兄弟の最後の要素に置き換えます(左の兄弟は1つのノードを失いますが、少なくとも最小数の要素があります)
木はバランスが取れています
それ以外の場合、両方の直接の兄弟に最小数の要素しかない場合は、親から取り外されたセパレーターを挟んでいる兄弟とマージします
セパレーターを左側のノードの最後にコピーします(左側のノードが不足しているノードであるか、最小数の要素を持つ兄弟である可能性があります)
すべての要素を右側のノードから左側のノードに移動します(左側のノードには最大数の要素があり、右側のノードは空です)
空の右の子とともに親からセパレータを削除します(親は要素を失います)
親がルートであり、要素がない場合は、親を解放して、マージされたノードを新しいルートにします(ツリーが浅くなります)
それ以外の場合、親の要素数が必要な数より少ない場合は、親のバランスを取り直してください
注:リバランス操作は、B +ツリー(たとえば、親がキーのコピーを持っているためにローテーションが異なる)とB *ツリー(たとえば、3つの兄弟が2つの兄弟にマージされる)で異なります。
シーケンシャルアクセス
新しくロードされたデータベースは良好なシーケンシャル動作をする傾向がありますが、データベースが大きくなるにつれてこの動作を維持することがますます困難になり、ランダムなI / Oとパフォーマンスの問題が発生します。
初期工事
一般的な特殊なケースは、最初は空のBツリーに事前にソートされた大量のデータを追加することです。一連の連続した挿入を単純に実行することはかなり可能ですが、ソートされたデータを挿入すると、ほぼ完全に半分いっぱいのノードで構成されるツリーになります。代わりに、特別な「バルクローディング」アルゴリズムを使用して、より高い分岐係数を持つより効率的なツリーを生成できます。
入力がソートされると、すべての挿入はツリーの右端にあり、特にノードが分割されるたびに、左半分でこれ以上挿入が行われないことが保証されます。一括読み込みの場合、これを利用し、過剰なノードを均等に分割する代わりに、可能な限り不均等に分割します。左側のノードを完全にいっぱいのままにして、キーがゼロで子が1つある右側のノードを作成します(通常のB-に違反します)。ツリールール)。
バルクロードの終了時に、ツリーはほぼ完全に完全なノードで構成されます。各レベルの右端のノードのみが満杯に満たない場合がこれらのノードも半分未満である可能性があるため、通常のBツリールールを再確立するには、そのようなノードを(完全に保証された)左の兄弟と組み合わせ、キーを分割して、少なくとも半分がいっぱいの2つのノードを生成します。完全な左兄弟がない唯一のノードはルートであり、半分未満であることが許可されています。
ファイルシステム内
データベースでの使用に加えて、Bツリー(または§バリアント)はファイルシステムでも使用され、特定のファイル内の任意のブロックへの迅速なランダムアクセスを可能にします。基本的な問題は、ファイルブロックを回転させることです I {i}
ディスクブロック(またはおそらくシリンダーヘッドセクター)アドレスへのアドレス。
一部のオペレーティングシステムでは、ファイルの作成時にユーザーがファイルの最大サイズを割り当てる必要がその後、ファイルを連続したディスクブロックとして割り当てることができます。その場合、ファイルブロックアドレスを変換するには I {i}
オペレーティングシステムは、ディスクブロックアドレスにファイルブロックアドレスを追加するだけです。 I {i}
ファイルを構成する最初のディスクブロックのアドレスに。スキームは単純ですが、ファイルは作成されたサイズを超えることはできません。
他のオペレーティングシステムでは、ファイルを大きくすることができます。結果のディスクブロックは連続していない可能性があるため、論理ブロックを物理ブロックにマッピングする方が複雑です。
たとえば、MS-DOSは単純なファイルアロケーションテーブル(FAT)を使用していました。FATには各ディスクブロックのエントリがあり、そのエントリはそのブロックがファイルによって使用されているかどうか、使用されている場合はどのブロックが同じファイルの次のディスクブロックであるかを識別します。したがって、各ファイルの割り当ては、テーブル内のリンクリストとして表されます。ファイルブロックのディスクアドレスを見つけるために I {i}
、オペレーティングシステム(またはディスクユーティリティ)は、FAT内のファイルのリンクリストに順番に従う必要がさらに悪いことに、空きディスクブロックを見つけるには、FATを順番にスキャンする必要がMS-DOSの場合、ディスクとファイルが小さく、FATのエントリが少なく、ファイルチェーンが比較的短いため、これは大きなペナルティではありませんでした。でFAT12のファイルシステム(フロッピーディスクと初期ハードディスクに使用される)、そこを超えない4080であったのエントリ、及びFATは、通常、メモリに常駐することになります。ディスクが大きくなるにつれて、FATアーキテクチャはペナルティに直面し始めました。FATを使用する大容量ディスクでは、読み取りまたは書き込みを行うファイルブロックのディスク位置を学習するために、ディスク読み取りを実行する必要がある場合が
TOPS-20(および場合によってはTENEX)は、Bツリーと類似した0から2レベルのツリーを使用しました。ディスクブロックは512個の36ビットワードでした。ファイルが512(2 9)ワードブロックに収まる場合、ファイルディレクトリはその物理ディスクブロックを指します。2つのファイルフィット場合は18の言葉は、そのディレクトリには、AUXインデックスを指します。そのインデックスの512ワードはNULL(ブロックが割り当てられていない)であるか、ブロックの物理アドレスを指します。2つのファイルフィット場合は27の言葉は、そのディレクトリには、AUX-AUXインデックスを保持しているブロックを指すでしょう。各エントリはNULLになるか、Auxインデックスを指します。その結果、2 27ワードファイルの物理ディスクブロックは、2回のディスク読み取りに配置され、3回目の読み取りで読み取られる可能性が
AppleのファイルシステムHFS +、MicrosoftのNTFS、 AIX(jfs2)、およびbtrfsやExt4などの一部のLinuxファイルシステムはBツリーを使用します。
B * -treesは、HFSおよびReiser4 ファイルシステムで使用されます。
DragonFly BSDのHAMMERファイルシステムは、変更されたB +ツリーを使用します。
パフォーマンス
Bツリーは、リンクリストの線形性よりも、データ量の増加に伴って成長が遅くなります。スキップリストと比較すると、両方の構造のパフォーマンスは同じですが、Bツリーはnの増加に合わせてスケーリングします。T-treeは、ためのメインメモリデータベースシステム、類似しているが、よりコンパクトです。
バリエーション
並行性へのアクセス
LehmanとYao は、各レベルのツリーブロックを「次の」ポインタでリンクすることにより、すべての読み取りロックを回避できる(したがって、同時アクセスが大幅に改善される)ことを示しました。これにより、挿入操作と検索操作の両方がルートからリーフに下がるツリー構造になります。書き込みロックは、ツリーブロックが変更されたときにのみ必要です。これにより、複数のユーザーによるアクセスの同時実行性が最大化されます。これは、データベースやその他のBツリーベースのISAMストレージ方式に関する重要な考慮事項です。この改善に関連するコストは、通常の操作中に空のページをbtreeから削除できないことです。(ただし、ノードのマージを実装するためのさまざまな戦略、およびソースコードについてはを参照して)
1994年に付与された米国特許5283894は、「メタアクセス方式」を使用して、ロックなしでB +ツリーへの同時アクセスと変更を可能にする方法を示しているようです。この手法は、ブロックキャッシュ内の各レベルのブロックを指す追加のメモリ内インデックスを使用して、検索と更新の両方でツリーに「上向き」にアクセスします。LehmanやYaoのように、削除のための再編成は必要なく、各ブロックに「次の」ポインタはありません。
並列アルゴリズム
Bツリーは構造が赤黒木と類似しているため、赤黒ツリーの並列アルゴリズムをBツリーにも適用できます。
も参照してください
B +ツリー
Rツリー
赤黒木
2–3ツリー
2–3–4ツリー
ノート
^ FATの場合、ここで「ディスクブロック」と呼ばれるものは、FATドキュメントで「クラスター」と呼ばれるものです。これは、1つ以上の連続する物理ディスクセクター全体の固定サイズのグループです。この説明では、クラスターは物理セクターと大きな違いはありません。
^ これらのうち2つは特別な目的のために予約されていたため、実際にディスクブロック(クラスター)を表すことができるのは4078のみでした。
参考文献
^ バイエル、R。; McCreight、E。(1970年7月)。「大規模な順序付けされたインデックスの編成と保守」 (PDF)。データの説明、アクセス、および制御に関する1970 ACM SIGFIDET(現在はSIGMOD)ワークショップの議事録-SIGFIDET’70。ボーイング科学研究所。NS。107. doi:10.1145 /1734663.1734671。S2CID 26930249。
^ Comer1979。
^ Bayer&McCreight1972。
^ Comer 1979、p。123脚注1。
^ Weiner、Peter G.「4 – EdwardMMcCreight」–Vimeo経由。
^ 「専門家開発のためのスタンフォードセンター」。scpd.stanford.edu。
^ Folk&Zoellick 1992、p。362。
^ Folk&Zoellick1992。
^ Knuth 1998、p。483。
^ Folk&Zoellick 1992、p。363。
^ Bayer&McCreight(1972)は、インデックス要素は( x、 a)の(物理的に隣接する)ペアであり、 xはキーであり、aはいくつかの関連情報であると述べて問題を回避しました。関連する情報は、ランダムアクセスの1つまたは複数のレコードへのポインタである可能性がありますが、それが何であるかは実際には重要ではありませんでした。Bayer&McCreight(1972)は、「この論文では、関連する情報はこれ以上重要ではない」と述べています。
^ Folk&Zoellick 1992、p。379。
^ Knuth 1998、p。488。
^ Tomašević、ミロ(2008)。アルゴリズムとデータ構造。セルビア、ベオグラード:Akademska misao pp。274–275。ISBN
978-86-7466-328-8。
^ Rigin AM、Shershakov SA(2019-09-10)。「Bツリー変更を使用したデータインデックス作成のためのSQLiteRDBMS拡張機能」。RASのシステムプログラミング研究所の議事録(ISP RASの議事録)。RASシステムプログラミング研究所(ISPRAS)。土井:10.15514 / ispras-2019-31(3)-16 。2021-08-29を取得。
^ カウントされたBツリー、
^ Seagate Technology LLC、製品マニュアル:Barracuda ES.2 Serial ATA、Rev。F。、出版物100468393、2008 、6ページ
^ Kleppmann、Martin(2017)、Designing Data-Intensive Applications、Sebastopol、California:O’Reilly Media、p。80、ISBN
978-1-449-37332-0
^ Comer 1979、p。127; コーメンら。2001年、439〜440ページ
^ 「忘却のBツリーをキャッシュする」。ニューヨーク州立大学(SUNY)のストーニーブルック。
^ マーク・ルシノビッチ。「Win2KNTFSの内部、パート1」。Microsoft DeveloperNetwork。
^ マシューディロン(2008-06-21)。「ハンマーファイルシステム」(PDF)。
^ リーマン、フィリップL。; 八尾さん ビング(1981)。「Bツリーでの同時操作のための効率的なロック」。データベースシステムでのACMトランザクション。6(4):650–670。土井:10.1145 /319628.319663。S2CID 10756181。
^ http://www.dtic.mil/cgi-bin/GetTRDoc?AD=ADA232287&Location=U2&doc=GetTRDoc.pdf
^ 「ダウンロード-high-concurrency-btree-Cの高同時性Bツリーコード-GitHubプロジェクトホスティング」。
^ 「キャッシュされたノードのためのロックレス同時Bツリーインデックスメタアクセス方法」。
全般的
バイエル、R。; McCreight、E。(1972)、”Organization and Maintenance of Large Ordered Indexes” (PDF)、Acta Informatica、1(3):173–189、doi:10.1007 / bf00288683、S2CID 29859053
Comer、Douglas(1979年6月)、「The Ubiquitous B-Tree」、Computing Surveys、11(2):123–137、doi:10.1145 / 356770.356776、ISSN 0360-0300、S2CID 101673。
コーメン、トーマス; レイザーソン、チャールズ; リベスト、ロナルド; Stein、Clifford(2001)、Introduction to Algorithms(Second ed。)、MIT Press and McGraw-Hill、pp。434–454、ISBN 0-262-03293-7。第18章:Bツリー。
フォーク、マイケルJ。; Zoellick、Bill(1992)、File Structures(2nd ed。)、Addison-Wesley、ISBN 0-201-55713-4
Knuth、Donald(1998)、Sorting and Searching、The Art of Computer Programming、Volume 3(Second ed。)、Addison-Wesley、ISBN 0-201-89685-0 |volume=余分なテキストがあります(ヘルプ)。セクション6.2.4:多方向ツリー、pp。481–491。また、セクション6.2.3(バランスの取れたツリー)の476〜477ページでは、2〜3ツリーについて説明しています。
オリジナルペーパー
バイエル、ルドルフ; McCreight、E。(1970年7月)、大量注文インデックスの編成と保守、数学および情報科学レポートNo. 20、ボーイング科学研究所。
Bayer、Rudolf(1971)、仮想メモリ用のバイナリBツリー、1971年の議事録ACM-SIGFIDET Workshop on Data Description、Access and Control、San Diego、California。
外部リンク
コモンズには、Bツリーに関連するメディアが
SJSUのDavidScotTaylorによるBツリー講義
Bツリーの視覚化(「初期化」をクリック)
アニメーション化されたBツリーの視覚化
ScholarpediaキュレーターのBツリーとUBツリー:ルドルフバイヤー博士
Bツリー:バランスの取れたツリーデータ構造
NISTのアルゴリズムとデータ構造の辞書:Bツリー
Bツリーチュートリアル
InfinityDBBTreeの実装
忘却のB(+)ツリーをキャッシュする
B *ツリーのアルゴリズムとデータ構造エントリの辞書
オープンデータ構造-セクション14.2-Bツリー、Pat Morin
カウントされたBツリー
B-Tree .Net、最新の仮想化されたRAMおよびディスクの実装
一括読み込み
Shetty、Soumya B.(2010)。ユーザーが構成可能なBツリーの実装(論文)。アイオワ州立大学。
Kaldırım、Semih「ファイル編成、ISAM、B +ツリーおよび一括読み込み」 (PDF)。トルコ、アンカラ:ビルケント大学。pp。4–6。
「ECS165B:データベースシステムの実装:講義6」 (PDF)。カリフォルニア大学デービス校。p。23。
「SQLServer2017のBULKINSERT(Transact-SQL)」。Microsoftドキュメント。”