Head-related_transfer_function
頭部伝達関数(HRTF )は、解剖学的伝達関数(ATF)とも呼ばれ、は耳の特徴を表す応答です。空間内のある点から音を受け取ります。音がリスナーに当たると、頭、耳、外耳道のサイズと形状、頭の密度、鼻腔と口腔のサイズと形状がすべて音を変換し、音の知覚に影響を与え、一部の周波数を上げ、他の周波数を減衰させます。一般的に、HRTFは、2,700Hzで+17dBの一次共振で2〜5kHzの周波数をブーストします。しかし、応答曲線は単一のバンプよりも複雑で、広い周波数スペクトルに影響を与え、人によって大きく異なります。
HRTFフィルタリング効果
2つの耳用のHRTFのペアを使用して、空間の特定のポイントから発生しているように見えるバイノーラルサウンドを合成できます。これは伝達関数であり、特定のポイントからの音がどのように耳(通常は外耳道の外端)に到達するかを記述します。ステレオ(2スピーカー)ヘッドホンからサラウンドサウンドを再生するように設計された一部の民生用ホームエンターテインメント製品は、HRTFを使用しています。スピーカーからのサラウンドサウンドの再生をシミュレートするために、HRTF処理のいくつかの形式もコンピューターソフトウェアに含まれています。
人間の耳は2つだけですが、音は3次元で、範囲(距離)、上下方向(仰角)、前後、および両側(方位角)に配置できます。これが可能なのは、脳、内耳、外耳(耳介)が連携して位置を推測するためです。音源をローカライズするこの機能は、人間や祖先で進化の必需品として開発された可能性が目は視聴者の周りの世界の一部しか見ることができず、暗闇では視覚が妨げられますが、音源をローカライズする機能は周囲の光に関係なく、すべての方向、さまざまな精度で 。
人間は、片方の耳から得られた手がかり(モノラル手がかり)を取り、両方の耳で受け取った手がかり(差の手がかりまたは両耳の手がかり)を比較することによって、音源の位置を推定します。違いの手がかりの中には、到着の時間差と強度の違いがモノラルの手がかりは、音源と人体の相互作用に由来します。元の音源の音は、聴覚系で処理するために外耳道に入る前に変更されます。これらの変更は、ソースの場所をエンコードし、ソースの場所と耳の場所に関連するインパルス応答を介してキャプチャされる場合がこのインパルス応答は、頭部伝達インパルス応答(HRIR)と呼ばれます。任意のソースサウンドをHRIRで畳み込むと、リスナーの耳がレシーバーの場所にある状態で、ソースの場所で再生された場合にリスナーが聞いたサウンドに変換されます。HRIRは、仮想サラウンドサウンドを生成するために使用されてきました。
HRTFは、HRIRのフーリエ変換です。
左耳と右耳のHRTF(上記ではHRIRとして表されます)は、左耳と右耳でそれぞれx L(t)とx R(t )として認識される前の音源(x(t ))のフィルタリングを表します。
HRTFは、自由空気中の方向から鼓膜に到達するときの音への音の変更として説明することもできます。これらの変更には、リスナーの外耳の形状、リスナーの頭と体の形状、サウンドが再生される空間の音響特性などが含まれます。これらすべての特性は、リスナーが音がどの方向から来ているかを正確に判断する方法(またはかどうか)に影響します。
AES69-2015規格では、 Audio Engineering Society(AES)は、頭部伝達関数(HRTF)のような空間指向の音響データを保存するためのSOFAファイル形式を定義しています。SOFAソフトウェアライブラリとファイルは、SofaConventionsWebサイトで収集されます。
コンテンツ
1 HRTFのしくみ
2 技術的派生
2.1 仮想聴覚空間における音像定位 2.2 HRTF位相合成 2.3 HRTFマグニチュード合成
3 録音技術
4 も参照してください
5 参考文献
6 外部リンク
HRTFのしくみ
頭と耳の形が異なるため、関連するメカニズムは個人によって異なります。
HRTFは、音が鼓膜と内耳の伝達機構に到達する前に、特定の音波入力(周波数と音源の位置としてパラメータ化)が頭部、耳介、胴体の回折および反射特性によってどのようにフィルタリングされるかを記述します(聴覚系を参照) )。生物学的には、これらの外部構造の音源位置固有のプレフィルタリング効果は、音源位置の神経決定、特に音源の高さの決定に役立ちます(垂直方向の音像定位を参照)。
技術的派生

耳の周波数応答のサンプル:
緑の曲線:左耳 X L( f)
青い曲線:右耳X R( f) 上向きの音源用。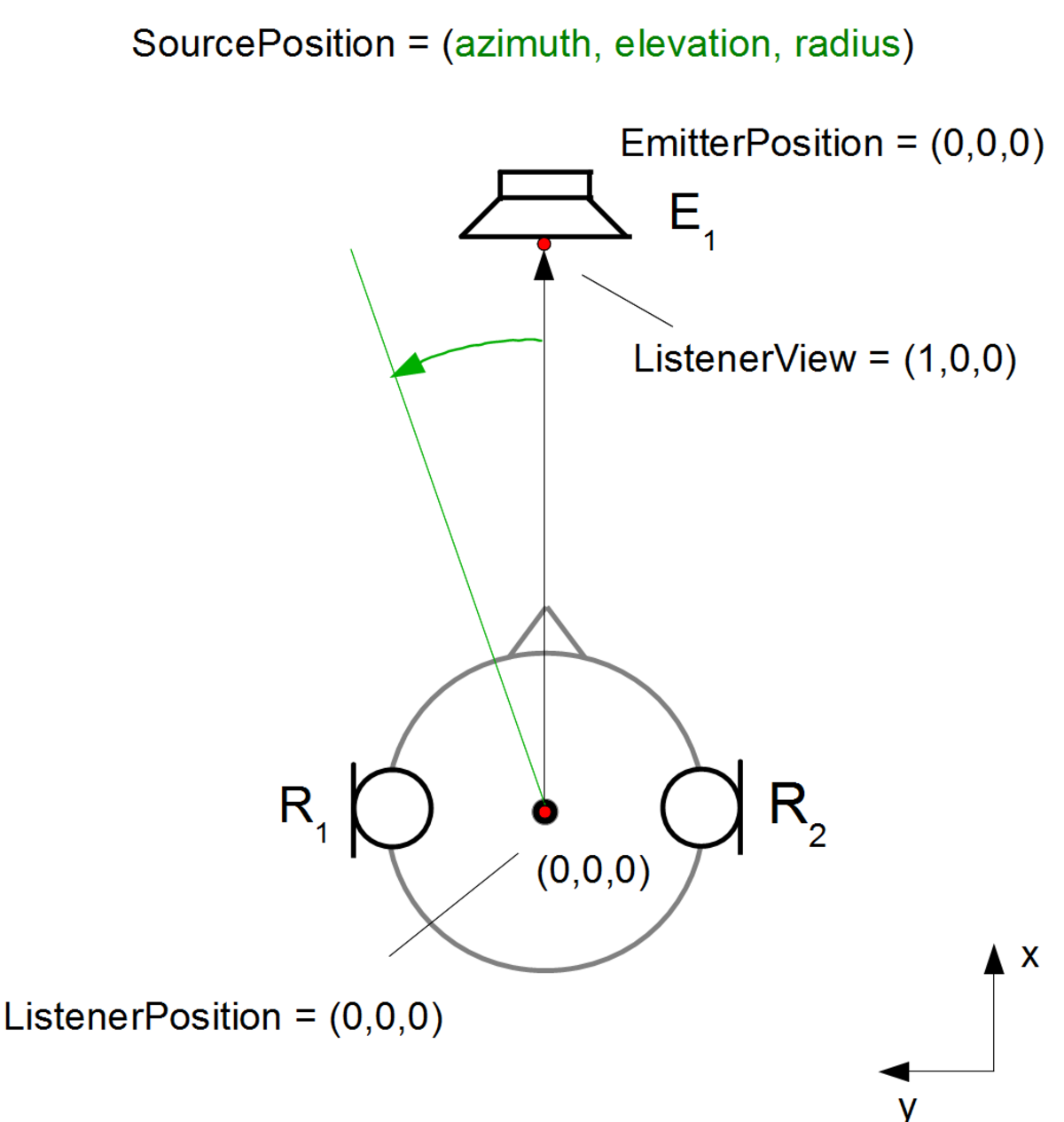
基準点から取得した方位角によるHRTF傾斜の例
線形システム分析では、伝達関数を、周波数の関数としての出力信号スペクトルと入力信号スペクトルの間の複素比として定義します。Blauert(1974; Blauert、1981で引用)は、当初、伝達関数を自由場伝達関数(FFTF)として定義していました。他の用語には、フリーフィールドから鼓膜への伝達関数、およびフリーフィールドから鼓膜への圧力変換が含まれます。あまり具体的でない説明には、耳介伝達関数、外耳伝達関数、耳介応答、または方向性伝達関数(DTF)が含まれます。
周波数fでの線形時不変システムの伝達関数H(f )は次のとおりです。
H(f)=出力(f)/入力(f)
したがって、特定のソース位置からHRTFを取得するために使用される1つの方法は、ソースに配置されたインパルスΔ(t )の鼓膜での頭部伝達インパルス応答(HRIR) h(t )を測定することです。HRTF H(f)は、HRIR h(t )のフーリエ変換です。
理想化された形状の「ダミーヘッド」で測定された場合でも、HRTFは周波数と3つの空間変数の複雑な関数です。ただし、頭部から1 mを超える距離では、HRTFは範囲に反比例して減衰すると言えます。最も頻繁に測定されるのは、この遠方場HRTF、H(f、θ、φ )です。近距離では、遠方界で無視できるレベル差が観察される低周波数領域でも、耳の間で観察されるレベルの差が非常に大きくなる可能性が
HRTFは通常、無響室で測定され、測定された応答に対する初期反射と残響の影響を最小限に抑えます。HRTFは、水平面内で15°や30°などのθの小さな増分で測定され、θの任意の位置のHRTFを合成するために補間が使用されます。ただし、増分が小さい場合でも、補間によって前後の混乱が生じる可能性があり、補間手順の最適化は活発な研究分野です。
測定されたHRTFの信号対雑音比(SNR)を最大化するには、生成されるインパルスが大量であることが重要です。ただし、実際には、大量のインパルスを生成することは困難であり、生成された場合、人間の耳に損傷を与える可能性があるため、周波数掃引正弦波を使用して周波数領域でHRTFを直接計算するのが一般的です。または最大長のシーケンスを使用します。ただし、ユーザーの疲労は依然として問題であり、より少ない測定値に基づいて補間する機能の必要性が浮き彫りになっています。
頭部伝達関数は、コーンの「0」部分の周りの多くの場所からの音源に対してITDとILDが同一である一連のポイントであるコーンオブコンフュージョンの解決に関与します。音が耳に届くと、耳を真っ直ぐ下って外耳道に入るか、耳介から反射して数分の1秒後に外耳道に入ることができます。音には多くの周波数が含まれるため、この信号の多くのコピーは、周波数に応じて(反射、回折、および高周波数と低周波数との相互作用、およびこれらのコピーは互いに重なり合っており、この間、特定の信号が強調され(信号の位相が一致する場合)、他のコピーはキャンセルされます(信号の位相が一致しない場合)。基本的に、脳は特定の既知の音の方向に対応する信号の周波数ノッチを探しています。
他の人の耳が代用された場合、強調とキャンセルのパターンはその人の聴覚システムが慣れているパターンとは異なるため、その人はすぐに音を定位することができません。ただし、数週間後、聴覚システムは新しい頭部伝達関数に適応します。 HRTFのスペクトルの被験者間変動は、クラスター分析を通じて研究されています。
人の耳の間の変化による変化を評価することで、頭の自由度と空間領域との関係で視点を制限することができます。これにより、複雑さを増す傾斜やその他の座標パラメータを排除します。キャリブレーションの目的で、私たちは耳への方向レベルのみに関心があり、特定の自由度をエルゴします。HRTFを較正するための式を推定できるいくつかの方法は次のとおりです。
仮想聴覚空間における音像定位
HRTF位相合成
HRTFマグニチュード合成
仮想聴覚空間における音像定位
仮想聴覚空間を作成する際の基本的な前提は、聴取者の鼓膜に存在する音響波形がヘッドホンの下で自由音場と同じである場合、聴取者の経験も同じでなければならないということです。
通常、ヘッドホンから生成される音は、頭の中から発生していると認識されます。仮想聴覚空間では、ヘッドホンは音を「外部化」できる必要がHRTFを使用すると、以下で説明する手法を使用して、サウンドを空間的に配置できます。
x 1(t)がスピーカーを駆動する電気信号を表し、y 1(t)がリスナーの鼓膜内のマイクによって受信される信号を表すとします。同様に、x 2(t)がヘッドフォンを駆動する電気信号を表し、y 2(t)が信号に対するマイクの応答を表すとします。仮想聴覚空間の目標は、y 2(t)= y 1(t )となるようにx 2(t)を選択することです。これらの信号にフーリエ変換を適用すると、次の2つの方程式が得られます。 Y 1 = X 1 LFM、および Y 2 = X 2 HM、
ここで、Lは自由音場でのスピーカーの伝達関数、FはHRTF、Mはマイクの伝達関数、Hはヘッドフォンから鼓膜への伝達関数です。Y 1 = Y 2を設定し、 X2を解くと X 2 = X 1 LF/H。
観察すると、目的の伝達関数は次のようになります。
T =
LF / H。 したがって、理論的には、x 1(t)がこのフィルターを通過し、結果のx 2(t)がヘッドホンで再生される場合、鼓膜で同じ信号が生成されるはずです。フィルタは片方の耳にのみ適用されるため、もう一方の耳には別のフィルタを導出する必要がこのプロセスは、仮想環境の多くの場所で繰り返され、サンプリング条件がナイキスト基準によって設定されていることを確認しながら、再作成される位置ごとに頭部伝達関数の配列を作成します。
HRTF位相合成
周波数帯域の非常に低い部分では信頼性の低い位相推定があり、高い周波数では、位相応答は耳介の特徴の影響を受けます。初期の研究では、HRTF位相応答はほとんど線形であり、波形の結合された低周波数部分の両耳間時間遅延(ITD)が維持されている限り、リスナーは両耳間位相スペクトルの詳細に鈍感であることが示されています。これは、方向と高度に応じて、時間遅延として対象のHRTFのモデル化された位相応答です。
スケーリング係数は、人体測定機能の関数です。たとえば、N人の被験者のトレーニングセットは、各HRTFフェーズを考慮し、単一のITDスケーリング係数をグループの平均遅延として記述します。この計算されたスケーリング係数は、特定の個人の方向と高度の関数として時間遅延を推定できます。時間遅延を左耳と右耳の位相応答に変換するのは簡単です。
HRTFフェーズは、ITDスケーリング係数で表すことができます。これは、参照のソースとして取得された特定の個人の人体測定データによって順番に定量化されます。一般的なケースでは、βをスパースベクトルと見なしますβ =
[ β
1 β
2 … β ] T { beta = [ beta _ {1}、 beta _ {2}、 ldots、 beta _ {N}] ^ {T}}
これは、被験者の人体測定の特徴をトレーニングデータからの人体測定の特徴の線形重ね合わせとして表し(y ‘ =βTX )、同じスパースベクトルをスケーリングベクトルHに直接適用します。このタスクを最小化問題として記述できます。 、非負の縮小パラメータλの場合:β = argmin β(( ∑a = 1 A(( ya −
∑ n =1 β nX n 2 )。+ λ ∑ n = 1 N β n )。 { beta = operatorname {argmin} Limits _ { beta} left( sum _ {a = 1} ^ {A} left(y_ {a}- sum _ {n = 1} ^ {N} beta _ {n} X_ {n} ^ {2} right)+ lambda sum _ {n = 1} ^ {N} beta _ {n} right)}
これから、ITDスケーリング係数値H ‘は次のように推定されます。H ′= ∑ n= 1 N β
n H n { H’= sum _ {n = 1} ^ {N} beta _ {n}H_{n}。}
ここで、データセット内のすべての人のITDスケーリング係数は、ベクトルH∈RNにスタックされているため、値Hnはn番目の人のスケーリング係数に対応します。
HRTFマグニチュード合成
最小絶対収縮および選択演算子(LASSO)を使用して、上記の最小化問題を解決します。HRTFは、人体測定機能と同じ関係で表されると想定しています。したがって、人体測定の特徴からスパースベクトルβを学習したら、それをHRTFテンソルデータと次の式で与えられる被験者のHRTF値H ‘に直接適用します。H d k ′= ∑ n= 1 N β
n H n d k
{ H’_ {d、k} = sum _ {n = 1} ^ {N} beta _ {n} H_ {n、d、k}}
ここで、各被験者のHRTFは、サイズD × Kのテンソルによって記述されます。ここで、DはHRTF方向の数、Kは周波数ビンの数です。すべてのHn、 d、kは、トレーニングセットのすべてのHRTFが新しいテンソルH∈RN×D×Kにスタックされることに対応するため、値H n 、d、kはdのk番目の周波数ビンに対応します。 n番目の人の-番目のHRTF方向。また、 H’d 、kは、合成されたHRTFのすべてのd番目のHRTF方向のk番目の周波数に対応します。
録音技術
リスナーのHRTFに近いコンピューターゲーム環境(A3D、EAX、OpenALを参照)などでHRTFを介して処理された録音は、ステレオヘッドホンまたはスピーカーで聞くことができ、すべての方向からの音で構成されているかのように解釈できます。 、頭の両側の2点だけではなく。結果の知覚精度は、HRTFデータセットが自分の耳の特性とどれだけ一致しているかによって異なります。
も参照してください
3Dサウンド再構成 A3D バイノーラル録音
ドルビーアトモス
ダミーヘッド録音
環境オーディオ拡張機能 OpenAL サウンド検索システム
音像定位
サウンドバー
センサウラ
伝達関数
参考文献
^ ダニエルスターチ(1908)。音像定位の視野検査。アイオワ州立大学。p。35ff。
^ Begault、DR(1994)仮想現実とマルチメディアのための3Dサウンド。APプロフェッショナル。
^ つまり、RHY、Leung、NM、Braasch、J. and Leung、KL(2006)頭部伝達関数に基づく、低コストの個別化されていないサラウンドサウンドシステム。人間工学研究とプロトタイプ開発。Applied Ergonomics、37、pp。695–707。
^ 「AES標準AES69-2015:ファイル交換のためのAES標準-空間音響データファイル形式」。www.aes.org 。
^ 「ソファコンベンションウェブサイト」。オーストリア科学アカデミーの研究所である音響研究所。
^ Blauert、J.(1997)空間ヒアリング:人間の音の局在化の心理物理学。MITプレス。
^ ホフマン、ポールM .; Van Riswick、JG; Van Opstal、AJ(1998年9月)。「新しい耳で音像定位を再学習する」(PDF)。ネイチャーニューロサイエンス。1(5):417–421。土井:10.1038/1633。PMID10196533。_ S2CID10088534。_
^ したがって、RHY、Ngan、B.、Horner、A.、Leung、KL、Braasch、J.およびBlauert、J.(2010)前方および後方指向性音の直交非個別化頭部伝達関数に向けて:クラスター分析と実験的研究。人間工学、53(6)、pp.767-781。
^ Carlile、S.(1996)。仮想聴覚空間とアプリケーション。テキサス州オースティン:Springer。ISBN 9783662225967。
^ Tashev、Ivan(2014)。「人体測定機能のスパース表現によるHRTF位相合成」。情報技術とアプリケーションワークショップ、米国カリフォルニア州サンディエゴ、会議論文:1–5。土井:10.1109/ITA.2014.6804239。ISBN 978-1-4799-3589-5。S2CID13232557 。_ ^ Bilinski、Piotr; アーレンス、イェンス; トーマス、マークRP; タシェフ、イワン; プラット、ジョンC(2014)。「人体測定機能のスパース表現によるHRTFマグニチュード合成」(PDF)。IEEE ICASSP、イタリア、フィレンツェ:4468–4472。土井:10.1109/ICASSP.2014.6854447。ISBN
978-1-4799-2893-4。S2CID5619011 。_
外部リンク
コモンズには、頭部伝達関数に関連するメディアが
空間サウンドチュートリアル
CIPICHRTFデータベース
HRTFデータベースを聞く
高解像度HRTFおよび3D耳モデルデータベース(48科目)
AIRデータベース(残響環境のHRTFデータベース)
NeumannKU100のフルスフィアHRIR/HRTFデータベース
MITデータベース(1つのデータセット)
ARI(音響研究所)データベース(90以上のデータセット)”