Su_(kana)
「す」は注音字母については、を参照してください
ㄡ。
す、に平仮名またはスでカタカナ、日本の一つである仮名一つを表しそれぞれが、モーラを。それらの形はそれぞれ漢字寸と寸から来ています。両方のかなは音を表します。でアイヌ語、カタカナはス最終Sを表すためにㇲ小さいように書くことができ、はなく、通常の[ɕ( ㇱとしてアイヌで表される)の発音を強調するために使用されます。 su ひらがな
カタカナ
文字変換 su 音訳。濁点 zu ひらがな起源 寸 カタカナの起源 須 万葉仮名
寸須周酒州洲珠数酢栖渚
有声万葉仮名
受受受儒
かなのつづり
すずめのす(すずめのすす)
フォーム ローマ字 ひらがな カタカナ
通常のs-(さ行さぎょう)
su す すす
SUU、SWU SU すう、ぅすすー
スウ、トゥススー
追加濁点 z-(ざ行ざぎょう)
zu ず ス
zuu、zwuzū ずう、ぅあずさあずさー
ズウ、トゥズズー
その他の追加フォーム
フォームA(sw-)
ローマ字
ひらがな
カタカナ swa すすス swi、si
すす
スィー* swe すすス swo
すす ス フォームB(zw-)
ローマ字
ひらがな
カタカナ zwa ずぁず zwi、zi
ずぃ
ズィー* zwe ずぇ
ズイzwo ず ズ
*スィーとズィーは、それぞれsiとziの発音を表すためにも使用されます。たとえば、「C」はスィー/siː/として表されます。ヘボン式ローマ字表記も参照して
筆順
筆順

筆順を書く
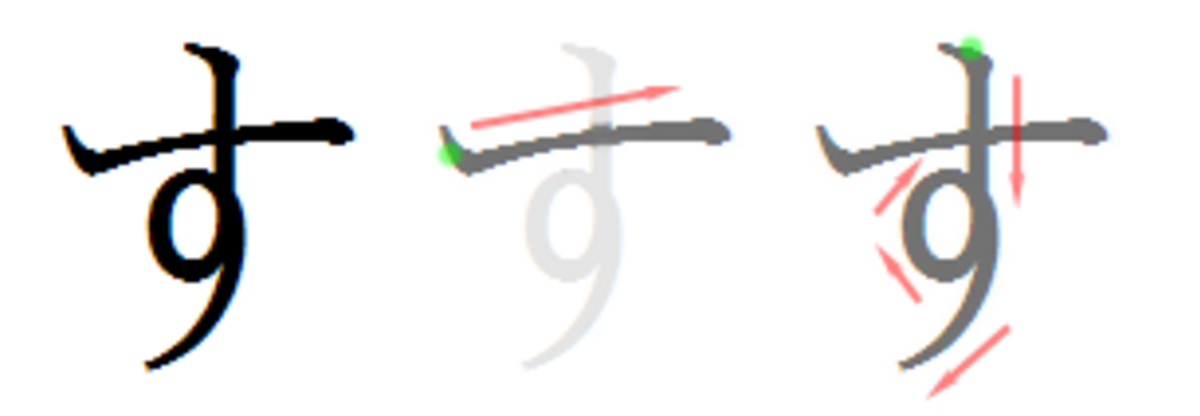
筆順

筆順を書く
その他のコミュニケーション表現
和文通話表のアルファベット
和文コード
すずめのスすずめない””蘇ありません””
▄▄▄▄▄▄▄▄▄▄▄▄▄
![]()
![]()
![]()

日本海軍信号旗
日本のセマフォ
指文字(指文字) 点字-1456 点字
完全な点字表現
すす/点字点字
す/スSU
ず/ズZU
すう/すす
ずう/ズーズー
点字すすをベースにした他のかな
しゅ/ししゅ
じゅ/ジュチュ
しゅう/しゅゅう
じゅう/ジュージュ
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
コンピュータエンコーディング
キャラクター情報
プレビュー す すす煤 ㋜
Unicode名 ひらがなレターSU カタカナレターSU HALFWIDTHカタカナレターSU 丸いカタカナSU
エンコーディング
10進数
ヘックス
10進数
ヘックス
10進数
ヘックス
10進数
ヘックスUnicode 12377
U + 3059 12473 U + 30B9 65405 U + FF7D 13020 U + 32DC UTF-8 227 129 153
E3 81 99 227130185 E3 82 B9 239189189 EF BD BD 227139156 E3 8B 9C
数値文字参照
す
す
ス
ス
ス
ス
㋜
㋜
シフトJIS 130 183 82 B7 131 88 83 58 189 BD
EUC-JP 164 185 A4 B9 165 185 A5 B9 142 189 8E BD
GB 18030 164 185 A4 B9 165 185 A5 B9
132 49 152 53
84 31 98 35
EUC-KR / UHC 170185 AA B9 171185 AB B9
Big5(非ETENかな)198 189 C6 BD 199 81 C7 51
Big5(ETEN / HKSCS)199 64 C7 40 199 181 C7 B5
キャラクター情報
プレビューㇲ ず ス
Unicode名 カタカナレタースモールSU ひらがなレターズ カタカナレターズ
エンコーディング
10進数
ヘックス
10進数
ヘックス
10進数
ヘックスUnicode 12786
U + 31F2 12378 U + 305A 12474 U + 30BAUTF-8 227135178
E3 87 B2
227 129 154
E3 81 9A 227130186 E3 82 BA
数値文字参照
ㇲ
ㇲ
ず
ず
ズ
ズ
シフトJIS(プレーン)130184 82 B8 131 89 83 59
シフトJIS-2004 131238 83 EE 130184 82 B8 131 89 83 59
EUC-JP(プレーン)164 186 A4 BA 165 186 A5 BA
EUC-JIS-2004 166240 A6 F0 164 186 A4 BA 165 186 A5 BA
GB 18030
129 57188 54
81 39 BC 36164 186 A4 BA 165 186 A5 BA
EUC-KR / UHC 170 186 AA BA 171 186 AB BA
Big5(非ETENかな)198190 C6 BE 199 82 C7 52
Big5(ETEN / HKSCS)199 65 C7 41 199 182
C7 B6
参考文献
ルックアップす、ず、ス、またはズウィクショナリー
^ Refsing、Kirsten(1996)。アイヌ語に関する初期のヨーロッパの著作。ロンドン:ラウトレッジ。ISBN 0-7007-0400-0。
^ ユニコードコンソーシアム(2015-12-02)。「Shift-JISからUnicodeへ」。
^ ユニコードコンソーシアム。IBM。「EUC-JP-2007」。Unicodeの国際コンポーネント。
^ 中国標準化管理委員会(SAC)(2005-11-18)。GB 18030-2005:情報技術-中国語でコード化された文字セット。
^ ユニコードコンソーシアム。IBM。「IBM-970」。Unicodeの国際コンポーネント。
^ Steele、Shawn(2000)。「cp949からUnicodeテーブルへ」。Microsoft / Unicodeコンソーシアム。
^ ユニコードコンソーシアム(2015-12-02)。「BIG5からUnicodeへのテーブル(完全)」。
^ van Kesteren、Anne。「big5」。エンコーディング標準。WHATWG。
^ プロジェクトX0213(2009-05-03)。「Shift_JIS-2004(JIS X 0213:2004付録1)とUnicodeマッピングテーブル」。
^ プロジェクトX0213(2009-05-03)。「EUC-JIS-2004(JIS X 0213:2004付録3)とUnicodeマッピングテーブル」。”